Análisis geoespacial en Python: Cluster KMeans, Voronoi y Open Street Map
Si bien los algoritmos de geometría computacional son conocidos en las distintas carreras relacionadas a la informática, la información referente a su integración con técnicas de Machine Learning es más bien escasa, o levemente referenciada, más no explorada en profundidad. Es por eso que en este artículo ahondaré sobre esa integración entre algoritmos y lo beneficioso que es para delimitar la «dominancia» de un clúster, para ello usaré el algoritmo de Voronoi por ser el algoritmo más útil ya que se puede usar los centroides de cada cluster para generar una región de Voronoi y con eso poder delimitar la región de cada cluster. También agregaré el código junto con un ejemplo de aplicación en el análisis geoespacial ya que este artículo se basa en un resumen en mi proyecto de investigación que hice en mi master el cual al igual que similar al título es sobre la aplicación de algoritmos no supervisados en el análisis geoespacial usando Voronoi y Open Street Map
Fundamentación teórica del análisis.
1. Optics, Kmeans, KNN o DBSCAN esa es la cuestión.
Aunque a menudo se hace uso de KMeans y KNN justificadamente, al ser los algoritmos de Machine Learning no supervisados más habituales, no se debe ignorar que otros tipos de algoritmos pueden tener ventajas computacionales o analíticas frente a los algoritmos anteriormente mencionados.
Por ejemplo, si se tiene un proyecto en el que se busca identificar el ruido dentro del conjunto de datos que están entre o alrededor de los clústers la elección de KMeans y KNN sería errónea ya que estos no son algoritmos para identificar el ruido como si lo puede hacer DBSCAN y OPTICS siendo estos similares entre sí, pero cuya diferencia principal radica en que DBSCAN usa un algoritmo de densidad mientras que OPTICS usa uno de proximidad, además DBSCAN es computacionalmente más rápido que OPTICS, por lo que, puede funcionar mejor para proyectos con un gran volumen de datos.
Por eso la eficiencia del modelo de datos que tengamos en mano a estudiar será más o menos eficiente según el tipo de algoritmo que escojamos y de cómo optimizamos sus parámetros en caso de que estos sean paramétricos, esto debido a que si dichos parámetros no se adecúan al conjunto de datos nuestro modelo presentará problemas como los que se mencionaron anteriormente para el caso de KMeans siendo los más habituales la asignación de peso distinto entre los datos, la mala selección de cantidad de clusters y la distribución anisotrópica de los datos.
2. La delimitación de clusters con Voronoi.
Los diagramas de Voronoi forman parte de los algoritmos fundamentales en el campo de la geometría computacional, en este caso más específicamente es un algoritmo de interpolación que resulta en un diagrama en base a una nube de puntos, y con ella, se estudia la proximidad de dichos puntos.
A partir de la distancia entre un par de puntos p y q se obtiene la media de la distancia || p – q || y con ello es posible trazar una recta en el diagrama que divida ambos puntos, este cálculo de medias repetido en cada uno de los puntos comparándolos entre sí da como resultado la generación del diagrama de Voronoi formado por los vértices como intersección entre dichas líneas formadas a partir de || p – q || y la región de Voronoi como resultado de la unión de dichos vértices. Esta región es la que posteriormente se usará como una visualización de la división geométrica de un clúster.
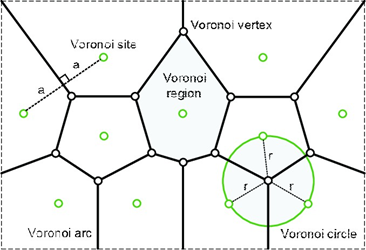
Fuente: Galishnikova, V. & Jan Pahl, P. (2018)
Con este tipo de diagrama se puede estudiar la proximidad entre un punto y los puntos de Voronoi, los cuales a partir de estos se obtiene todo el diagrama. Esto mismo podemos aplicarlo en los algoritmos de aprendizaje no supervisado de Machine Learning, convirtiendo los centroides como los puntos de Voronoi que se necesitan para poder hacer el diagrama entero sobre la visualización obtenida por un algoritmo no supervisado.
Esto es aplicable porque sigue una lógica clara: si se obtiene una nube de puntos con la cual formar un clúster en Machine Learning, de estos puntos se puede obtener su centroide y con ello aplicar esta técnica de geometría computacional.
3. Normas generales.
Teniendo en cuenta un conjunto de datos P, cuyos datos forman parte del conjunto a modo de P1, P2, P3…Px, entonces:
- Los puntos del conjunto P representan datos discretos.
- Los datos de P pueden usarse en un algoritmo no supervisado de Machine Learning.
- La representación gráfica de este conjunto aplicado a un algoritmo sirve como base para el modelado de un diagrama de Voronoi, esto con el fin de obtener una serie de clusters que definan dicho modelo.
- A partir de las regiones de Voronoi formadas por los clusters, se puede profundizar en la información contenida en dicho clúster como una forma de separar el espacio geográfico.
- Con la información que se pueda extraer de las regiones de Voronoi y clusters, se pueden realizar cálculos con los cuales mejorar el entendimiento de los datos y su contexto, con el fin de realizar conclusiones sobre dichos datos.
4. Explicación y funcionamiento.
El diagrama de Voronoi tiene múltiples aportes a los algoritmos de aprendizaje no supervisado en Machine Learning, siendo estos aportes principalmente:
- Trazar y comparar regiones de Voronoi con lo cual hacer seguimiento del comportamiento de los grupos y su pertenencia comparativa con los clúster más cercanos.
- Permite al analista de datos tener en mente una clara posibilidad de pertenencia de un punto a un determinado clúster u otro, a pesar de que esta información aún no esté dada.
- Estudiar la proximidad y los límites entre los diferentes centroides que conforman un clúster.
- Uso de los vértices como elemento geométrico para visualizar la zona común que existe entre un grupo de clusters próximos entre sí y separados cada uno por una región de Voronoi.
- A partir de los espacios vacíos generados en un diagrama de Voronoi, verificar si se cumple el tercer teorema, y estudiar la posible existencia de potenciales nuevos grupos por segmentar en la visualización de la clusterización.
Código para hacer el análisis geoespacial.
Con el fin de aplicar esta serie de «reglas» a un caso práctico para hacer más ilustrativa la explicación, se usarán datos reales sobre bares en el municipio de Chamberí, y a partir de dicha información se usarán los algoritmos para profundizar más en dicha información se buscará llegar a una conclusión: Teniendo en cuenta los datos para luego hacer un análisis geoespacial ¿En que zona de Chamberí sería mejor establecer un nuevo bar?
En cuanto a los datos para usar en el código, también dejo el grupo de puntos geoespaciales con latitud y longitud en formato de coordenadas de grados decimales convertidas a coordenadas estándar UTM-30 basado en el mapa UTM de España que para este caso serán bares, esta información luego puede usarse para comparar la dominancia de los clusters en el diagrama y comparar los datos entre sí. Las coordenadas de bares en UTM-30 de Chamberí se encuentran disponibles para descargar como archivo csv de los datos geoespaciales de bares en chamberí.
'''
#====================== DATOS Y ALGORITMOS ======================
'''
#Importación de librerias
import matplotlib.pyplot as plt
import osmnx as ox
from scipy.spatial import Voronoi, voronoi_plot_2d
from sklearn.cluster import KMeans
import pandas as pd
#Mapa del distrito
distrito = ox.graph_from_place('Chamberí, Madrid, Spain', network_type='drive')
streets_graph = ox.projection.project_graph(distrito)
streets = ox.graph_to_gdfs(ox.get_undirected(streets_graph), nodes=False, edges=True, fill_edge_geometry=True)
puntos = pd.read_csv('/home/usuario/documentos/mapeado.csv', header=None) #Datos
km = KMeans(n_clusters= 4, random_state=0).fit(puntos) #Modelo KMeans
'''
#====================== CREAR MAPA CON KMEANS VORONOI ======================
'''
#Crear el gráfico
f, ax = plt.subplots(figsize=(9, 9))
xmin, xmax = streets.total_bounds[0], streets.total_bounds[2]
ymin, ymax = streets.total_bounds[1], streets.total_bounds[3]
ax.set_xlim(xmin, xmax)
ax.set_ylim(ymin, ymax)
streets.plot(ax=ax, color='blue', alpha=0.5, zorder=1) # agregar el mapa de calles al gráfico
#Visualización de puntos y centroides
centers = km.cluster_centers_
plt.scatter(puntos[0], puntos[1], c=km.labels_, s=100)
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, marker='*')
plt.scatter(puntos[0], puntos[1], c=km.labels_, s=10, cmap='viridis')
#Voronoi
vor = Voronoi(centers)
voronoi_plot_2d(vor, ax=ax, show_vertices=True)
#Etiqueta y visualización final
plt.xlabel('Longitud')
plt.ylabel('Latitud')
plt.show()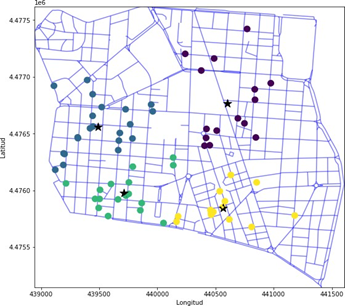
Figura 2. Mapa de bares en Chamberí usando OSMNX y KMeans optimizado a cuatro clusters.
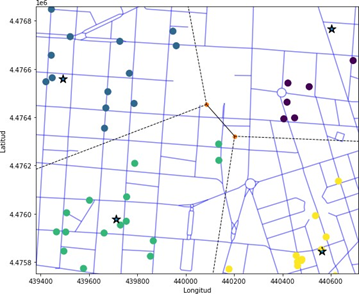
Figura 3. Mapa de FIG 2 con cuatro clusters basado en las coordenadas UTM30 de los bares en Chamberí separados con regiones demarcadas por Voronoi, como resultado de un diagrama para análisis geoespacial sobre la «dominancia» de cada clúster en un mapa.
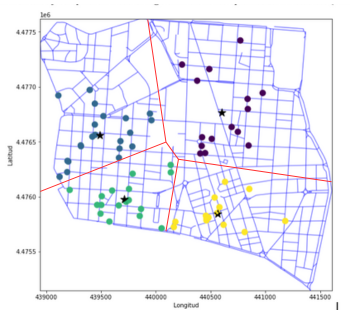
Figura 4. Mapa de FIG 3 extendiendo las delimitaciones de la división de clusters KMeans de forma «manual» para tener la visión completa sobre la división real sobre cada cluster para estudiarlos y compararlos individualmente con el resto.
Análisis geoespacial y otras aplicaciones.
Una vez que se tenga todo el procesamiento se puede empezar a usar la imagen de los resultados para hacer una inferencia analítica tanto sobre los datos como de la imagen final del código, por ejemplo usando de comparación cada clúster según otro tipo de empresas cercanas y ver si existe algún patrón lógico entre los ingresos de esas empresas respecto al clúster que pertenecen, etc.
En esta fase no puedo agregar el resto del ejemplo debido a que depende de lo que se quiera analizar, y va más orientado a la ambigüedad del objetivo del análisis que de un patrón más o menos organizado y metódico como puede ser el código que he dejado más arriba, así que eso implica que esta fase depende de quien lo analiza y no del método en sí. Pero la idea principal es que una vez delimitado los clusters, se pueden comparar y estudiar de forma individualizada, ya que en un grupo de datos grandes se puede cometer fallos al delimitar a ojo si un cierto punto pertenece o no al cluster ya sea Kmeans, KNN o el que sea, cosa que acaba resolviendo bastante bien el algoritmo de Voronoi.
Aplicación en marketing.
Esta unión entre Kmeans y Voronoi al tener unos clusters delimitados por una región de Voronoi o como me gusta llamarlo a mi, la dominancia del cluster, lo podemos aplicar también para el marketing, por ejemplo, en lugar de tener «latitud» o «longitud» de datos geoespaciales podríamos tener una relación entre ingresos de un grupo de usuarios y lo que suelen gastar, de forma que se podría optimizar una publicidad de forma más eficiente usando la región de Voronoi como una ayuda extra para delimitar una publicidad de marketing a un grupo dado, pero eso lo dejaré como un tema pendiente para otros artículos ya que a mi parecer este ejemplo con código es bastante completo.
Aplicación en medicina.
Citando al artículo de la Wikipedia que habla sobre el algoritmo de Voronoi: «Un uso particularmente notable fue en el análisis de la epidemia de cólera de1854 en Londres llevado a cabo por el médico John Snow, el cual determinó una fuerte correlación de muertes con la proximidad a una determinada bomba de agua —a la postre contaminada— en Broad Street (en el distrito de Soho)».
Incluso en el ámbito médico tiene su aplicación, aunque en aquella época los datos se agrupaban de forma manual sin usar algoritmos no supervisados, pero aún así eso lo que puede confirmar es que siempre y cuando tengas datos que puedas agrupar o «clusterizar» entonces si aplicas Voronoi podrás inferir de mejor manera en los datos comparándolos entre distintos clusters.
¿Necesitas un análisis geoespacial en tu proyecto de desarrollo?
Nosotros podemos ayudarte a desarrollar cualquier tipo de algoritmo que necesites, ya sea para procesar texto, imágenes o incluso ¡recomendar productos!